🚀 A powerful open‑access discovery tool that helps researchers locate legally available versions of academic papers using ethical, multi‑source search techniques.
Access to scientific knowledge should never depend on geography, sanctions, or financial barriers.
Ultimate Academic Paywall Bypass is a Python‑based tool that automatically searches across:
- ✅ Open‑access APIs (Unpaywall, CORE, Zenodo)
- ✅ Preprint servers (bioRxiv)
- ✅ Author‑uploaded repositories (institutional pages, ResearchGate, Academia.edu)
- ✅ Archival mirrors (Wayback Machine)
- ✅ Public search results (Google Scholar)
⚖️ This tool does NOT break paywalls. It automates what researchers already do manually — finding legal, open-access copies — but faster, smarter, and more reliably.
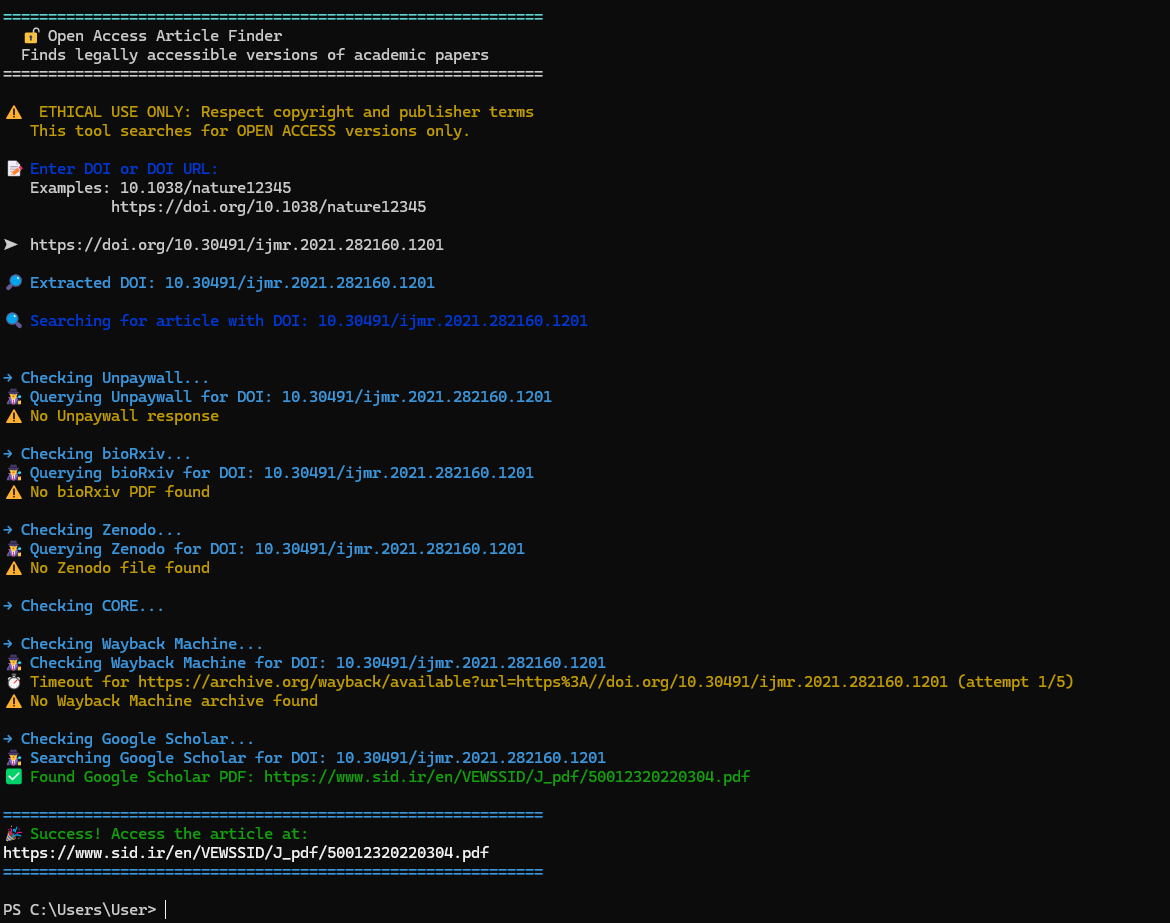
- Accepts raw DOIs (
10.1038/nature12345) or full DOI URLs (https://doi.org/10.1038/nature12345) - Automatic regex-based extraction and validation
Checks legal, public sources in order of reliability:
| Source | Type | Selenium Required |
|---|---|---|
| Unpaywall | API | ❌ |
| bioRxiv | API | ❌ |
| Zenodo | API | ❌ |
| CORE | API (key optional) | ❌ |
| Wayback Machine | API | ❌ |
| Google Scholar | Web scraping | ❌ |
| Author Profiles | Google search | ❌ |
| ResearchGate | Web scraping | ✅ Optional |
| ACS Publications | Web scraping | ✅ Optional |
- Capped exponential backoff with jitter
- Rotating User-Agent headers
- Respectful delays between requests (
REQUEST_DELAY = (1, 3)seconds) - Graceful timeout and error handling
- All activity logged to
paywall_bypass.log - Colored console output for real-time feedback
- Configurable log level via
logging.basicConfig()
- Headless Chrome with anti-detection options
- Toggle via
ENABLE_SELENIUM = True/False - Automatic driver initialization with error handling
- Credentials via environment variables (
UNPAYWALL_EMAIL,CORE_API_KEY) - No hardcoded secrets in source code
- Input validation on all URLs
git clone https://github.com/shataragh/ultimate-academic-paywall-bypass.git
cd ultimate-academic-paywall-bypass