the Convergence condition #95
-
|
Dear SSCHA developers, And I make minim.meaningful_factor = 0.0000005 |

Beta Was this translation helpful? Give feedback.
Replies: 4 comments 11 replies
-
|
Hi Zhao, |
Beta Was this translation helpful? Give feedback.
-
|
Thank you for your reply. Yeah, I'm asking these questions because I found in my output file the code end at FC gradient modulus = 535.20615236. I think maybe it is not mean "goes to zero". And I'm afraid if I set minim.meaningful_factor smaller it will take too much time.Even in this precision the code took almost two weeks. I do my work with vc_relax, it's there any suggestions for speeding up? |
Beta Was this translation helpful? Give feedback.
-
|
In my opinion, the precision kind of goes asymptotic with the number of configurations in the ensemble. You can speed up calculations by reducing the number of configurations in the ensemble to get 'closer' and then finish with a proper calculation. |
Beta Was this translation helpful? Give feedback.
-
|
Thank you very much for your patience. In this work at the end of the code. |
Beta Was this translation helpful? Give feedback.
-
|
As Ion says, increase the 'minim.min_step_dyn' and 'minim.min_step_struc' to make the calculation converge faster. Also 'N_configs = 1000' is OK, you can also calculate with 500 and compare results on the hessian. |
Beta Was this translation helpful? Give feedback.
-
|
For the second question. First note that the Kong-Liu ratio defines how 'good' is the current ensemble. As the calculation goes during the minimization process, the ensemble no longer describes well the probability distribution and a new ensemble needs to be obtained. So for a good minimization you have both a 'good' ensemble that describes the probability distribution and a pair of gradients (with respect to the trial centroids and harmonic matrix) that are lower than the threshold defined by 'min_step_struc' and 'min_step_dyn'. The threshold is re-defined (scaled) by the user provided variable 'meaningful_factor'. On the "How small is good enough? 1e-2 or 1e-12", I cannot provide you with a specific answer. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks diego for replying, |
Beta Was this translation helpful? Give feedback.
-
|
In order to speed up the minimization probably you need to increase the steps in the steepest descent minimization increasing the parameter min_step_dyn to something close to 1. Bringing the gradient to 0 (~1e-6) is a guarantee that your auxiliary phonons are not updating anymore. This is good. However, as the method is stochastic, this does not mean that this is the solution. The best practice is to take one half of your population, repeat the minimization, and see if the final converged result agree with the result obtained with the full population. Diego is right about the Hessian. We usually plot the value of the Hessian eigenvalues as a function of the number of configurations and see if the eigenvalues are converged with the number of configurations. |
Beta Was this translation helpful? Give feedback.
-
|
Hi Ion, by analyzing the output submitted, the code takes only 6-7 minutes to run (~2.3 seconds per step and converge after overall 166 steps), all the rest of the time is spent in the DFT calculations on a cluster connected remotely, which are 1000 over 5 populations. |
Beta Was this translation helpful? Give feedback.
-
|
Hi, As others answered, your calculation is converging very well. Especially the variable cell optimization. The result is Which you see that the starting point is 11.8 GPa (with quantum fluctuations) and ends to 10.004 +- 0.02 GPa Which is converged with respect your target pressure of 10 GPa. The values of FC and Struct gradients both are lower than the error. This means that your results for the free energy and first derivatives are well converged. Moreover, your code stopped with Kong-Liu at 945 effective configurations (out of 1000 I think), which means that, even if you decrease the meaningful factor to 1e-6, it will most likely remain as it is and not go outside the stochastic threshold any more (therefore not increasing significantly your time). |
Beta Was this translation helpful? Give feedback.
-
|
Regarding the question about the hessian, the test you made gives you an idea of the error. Take the smallest ones for example (excluding the 3 acoustic modes): You have 1.77e-3 Ry with 1000 configurations, and 1.66e-3 Ry with 500 configurations (if I understood correctly), therefore you can expect a 6 % error in your final results (1.77-1.66)/1.77 ~ 0.06 |
Beta Was this translation helpful? Give feedback.
-
|
Thanks to all of you's answers I think I may get it now. [About speed up calculation] |
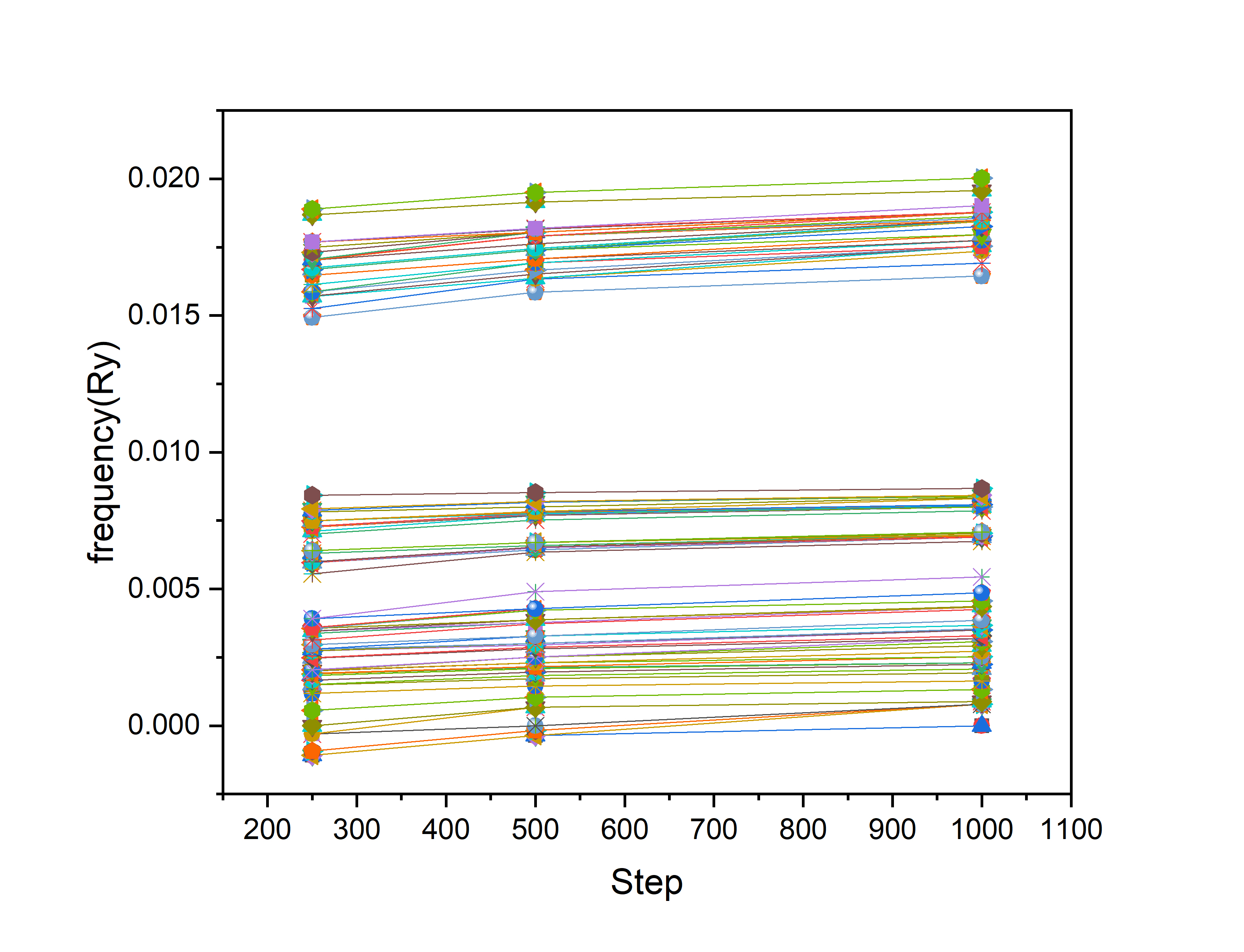
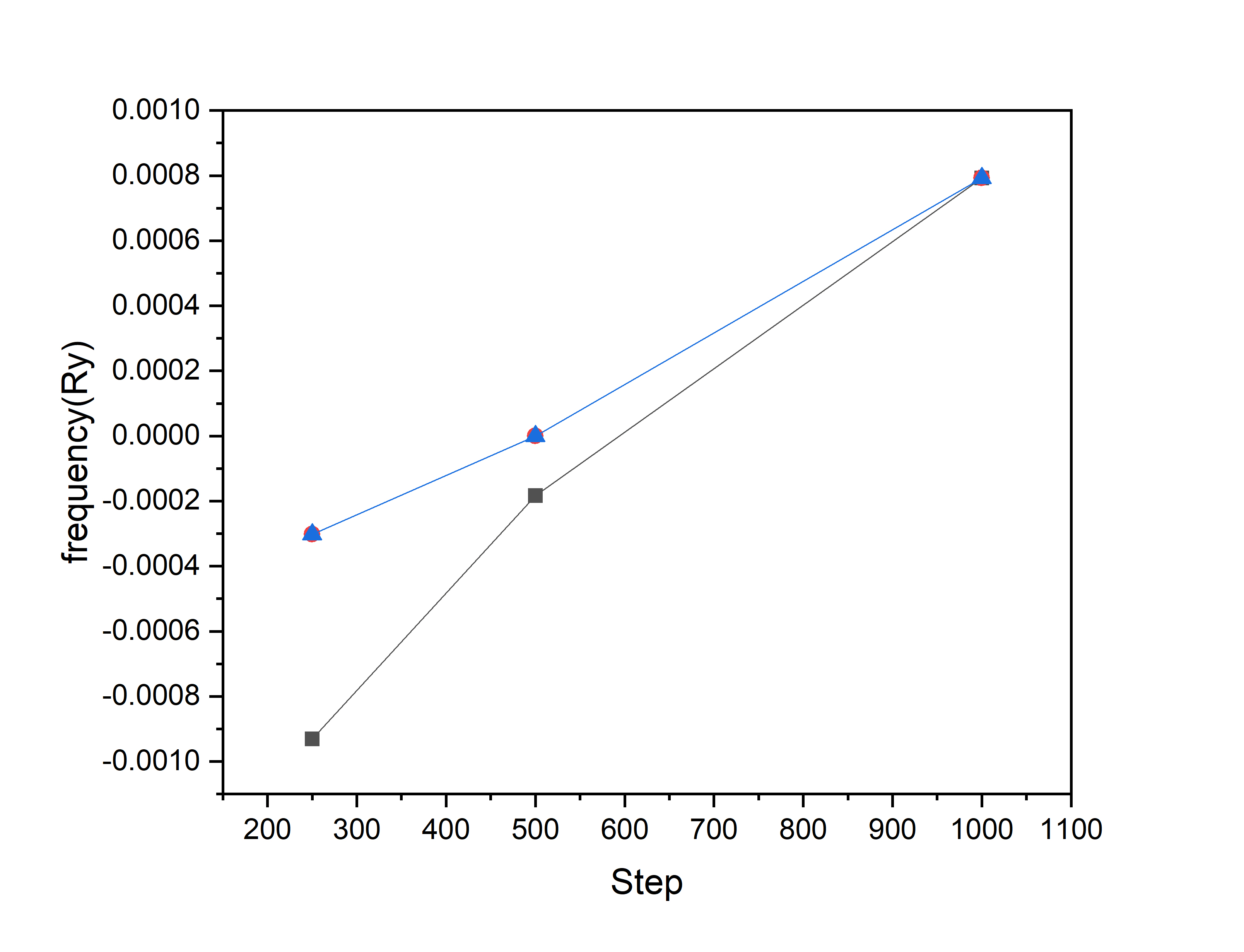
Beta Was this translation helpful? Give feedback.
-
|
Sorry I make a mistake in the x label .It's not "Step", it's "the number of configurations" |
Beta Was this translation helpful? Give feedback.
-
|
Hi, Regarding the vc-relax: Regarding the Free energy Hessian: Regarding the FC gradient to zero: |
Beta Was this translation helpful? Give feedback.
-
|
I get it. Thank you again for your reply and advice. |
Beta Was this translation helpful? Give feedback.
Hi, As others answered, your calculation is converging very well. Especially the variable cell optimization.
You can look how the Stress tensor evolves in the different population with respect to the target pressure you set up:
The result is